)
While generative AI models, especially larger models like GPT-4 and Gemini, work very well for all generative use cases, they are often expensive and “blackboxed” with latencies higher than expected. In contrast, the open community, with platforms like Hugging Face, offers numerous models for various tasks, contributing to rapid growth. Although open models are improving, they still lag in performance and reliability compared to proprietary models like GPT-4.
At Uniphore, we’ve developed a highly efficient fine-tuning methodology that turns smaller LLMs (and others) into truly formidable tools—and makes LLM-based AI more accessible to enterprises everywhere without sacrificing their needs for data privacy, cost and latency with high accuracy.
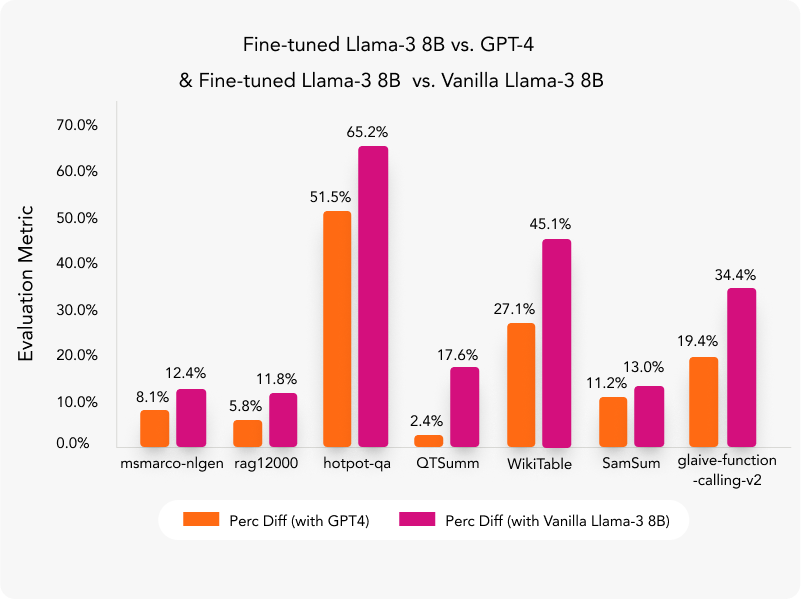
We benchmarked fine-tuned Llama-3 8B, Llama-3 8B Vanilla and GPT-4 on eight different datasets, covering tasks such as question answering (Q&A), Q&A with structured data/tables, named entity recognition (NER), summarization and agent-based functions that are most relevant for the enterprise AI space. As a result, we have achieved a 15% median increase in accuracy as compared to GPT-4 and a 26% median increase in performance as compared to Vanilla Llama-3 8B and an 11x reduction in inference cost.
We also developed our in-house framework with optimized code for parameter-efficient instruction fine-tuning of LLMs using the best-in-class available toolsets along with our modifications, which led to an eight-fold reduction in the training time. This allows us and our customers to instruction fine-tune models using our APIs in just a few hours based on their datasets and tasks, ensuring they work effectively for their applications.
Our methodology
At Uniphore, we have developed a low-code, highly optimized framework that enables users to fine-tune their models on custom datasets quickly and efficiently, with integrated evaluation capabilities. As a result, users can now:
- Train custom models easily and efficiently: using a low-code solution that allows users to fine-tune LLMs on their custom data very quickly.
- Achieve a high degree of optimization: integrating Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA and QLoRA, using distributed training methods like DeepSpeed.
- Access customizable components: checkpointing and best model selection based on custom metrics instead of validation set loss, ensuring better model selection. This includes out-of-the-box custom metrics for Q&A, NER and summarization tasks.
- Access out-of-the-box scripts: for quick and efficient evaluation for Q&A, NER and Summarization tasks.
- Better manage their data and model: with an easy solution for post-training management.
Making efficient LLM fine-tuning a reality
Like every learning task, we began by gathering datasets that correspond to the use cases of our customers and their applications. In this work, we covered five different task types: Q&A on text documents, Q&A on tables, NER, summarization and agent function calling and reasoning.
The table below details the statistics of the datasets chosen for fine-tuning. For some datasets, due to their large size, we used samples of smaller sizes to allow faster training and evaluation turnaround.
| Datasets | Link | Task Type | # Train | # Test | # Val |
|---|---|---|---|---|---|
| msmarco-nlgen | huggingface.co | Q&A | 10000 | 2700 | 300 |
| rag12000 | huggingface.co | Q&A | 9600 | 2040 | 360 |
| hotpot-qa | huggingface.co | Q&A | 10000 | 2000 | 400 |
| QTSumm | huggingface.co | Q&A (Table) | 4981 | 1078 | 400 |
| Wiki Table | huggingface.co | Q&A (Table) | 11321 | 4344 | 400 |
| Cross NER | huggingface.co | NER | 14741 | 5959 | 500 |
| samsum | huggingface.co | Summarization | 14732 | 819 | 400 |
| glaive function calling v2 | huggingface.co | Function Calling | 22000 | 4800 | 500 |
Training details
We utilized our proprietary framework to fine-tune the Llama3-8B model on the specified datasets. This low-code solution offers a wide range of customizable hyperparameters. We conducted the fine-tuning on all tasks using an A100 GPU, keeping the hyperparameters constant (as detailed below), since our primary objective was not hyperparameter tuning. On average, the training process for each model took about 1.5 hours. Our framework accepts a dictionary of these hyperparameters, with customizable defaults as follows:

Evaluation metrics
Q&A and summarization (composite similarity)
For Q&A and summarization that involves comparing texts, we found existing metrics, like ROUGE and cosine similarity, unreliable for our generative Q&A tasks, particularly in capturing full semantics and factual information. To address this, we developed Composite Similarity, which aligns significantly better with human accuracy evaluations.
The heatmap below highlights the correlation between the various metrics and the Evaluation Score, a continuous measure ranging from 0 to 1 that assesses answer correctness. This score represents either human or GPT-4 evaluations, comparing answers to reference responses. Through multiple experiments, we verified that GPT-4 closely approximates human assessments.
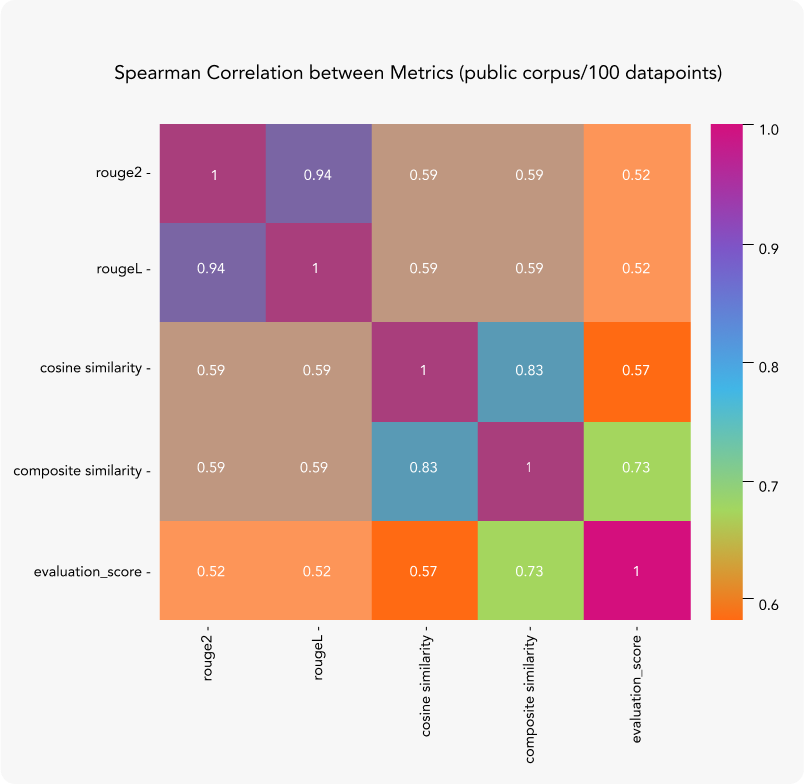
Composite Similarity achieves the highest correlation, a finding consistently verified across multiple datasets. The Spearman correlation values, ranging from 0.69 to 0.76, indicate a strong positive correlation.
NER (Named Entity Recognition) & Function Calling
For NER, we simply calculated the F1 scores of the extracted entities (full match). For the function calling task, which is a crucial requirement in the Agentic systems, we evaluated the accuracy of the predicted functions and their arguments from the LLM. All these evaluation methods are integrated into our framework, enabling quick and efficient evaluation.
Result: increased performance
Figure 1 (above) presents the results across various datasets, showcasing the percentage difference in evaluation metrics between the fine-tuned Llama3-8B model and its Vanilla version. The second comparison highlights the percentage difference between the fine-tuned model and GPT-4. In this context, the term “evaluation metric” is used generically to denote the specific metrics used for each task (e.g. Composite Similarity for Q&A). As evident from the chart, the comparison with the Vanilla version demonstrates the significant improvements achieved through fine-tuning, particularly in scenarios where zero-shot or in-context learning falls short. Additionally, the comparison with GPT-4 highlights that even a smaller 8B-parameter model can outperform the much larger GPT-4 when trained on the right dataset. This not only reduces inference costs significantly but also lowers latency, which is crucial in applications such as real-time intent detection.
Conclusion
Uniphore’s methodology and fine-tuning process results demonstrate a generalizable way of improving LLM performance and adaptability to specific applications for enterprise customers. Our solution opens the door to efficient specialization of smaller LLMs to achieve performance comparable to the largest general-purpose models. This results in a substantial reduction in inference costs providing full data and model governance and paving the way for a wider range of AI capabilities for the enterprise.
This methodology will be available as a service for our customers and will enable them to perform quick cycles of accuracy improvement and create models optimized for cost, latency and concurrency.